
Gemini 3.1 Flash-Lite: самая быстрая и дешёвая модель Google для высоких нагрузок (обзор 2026)
3 марта 2026 года Google показала новую модель в линейке Gemini — 3.1 Flash-Lite. Не «самую умную», не «прорывную по качеству рассуждений». А самую дешёвую и быструю. И это, пожалуй, интереснее.
Если у вас бот на 100 тысяч запросов в день, или конвейер классификации писем, или мультиязычный чат поддержки — Flash-Lite сделана именно под это. Давить стоимость токена вниз, отвечать за миллисекунды, не ломаться под нагрузкой.
Что изменилось: Flash-Lite в контексте линейки Gemini
Чтобы понять, зачем Flash-Lite существует, нужно посмотреть на всю линейку.
Gemini 3 Pro — флагман. Сложные рассуждения, длинные цепочки логики, задачи, где важно качество каждого ответа. Стоит соответственно.
Gemini 3 Flash — баланс: быстрее и дешевле Pro, но всё ещё хороша для задач средней сложности. Её можно попробовать через AI-Flip
А Flash-Lite — это ещё один шаг вниз по цене и вверх по скорости. Google прямо пишет: модель оптимизирована под высокообъёмные задачи с низкой задержкой. Перевод, классификация, извлечение данных. Не эссе на 10 страниц, не доказательство теорем.
Построена она на базе Gemini 3 Pro, но «обрезана» под скорость. Примерно как турбированный двигатель от седана, который поставили в курьерский фургон. Мощность чуть меньше — зато расход топлива в разы ниже, а едет быстрее. По такому же принципу строилась прошлая Gemini 3 Flash preview.
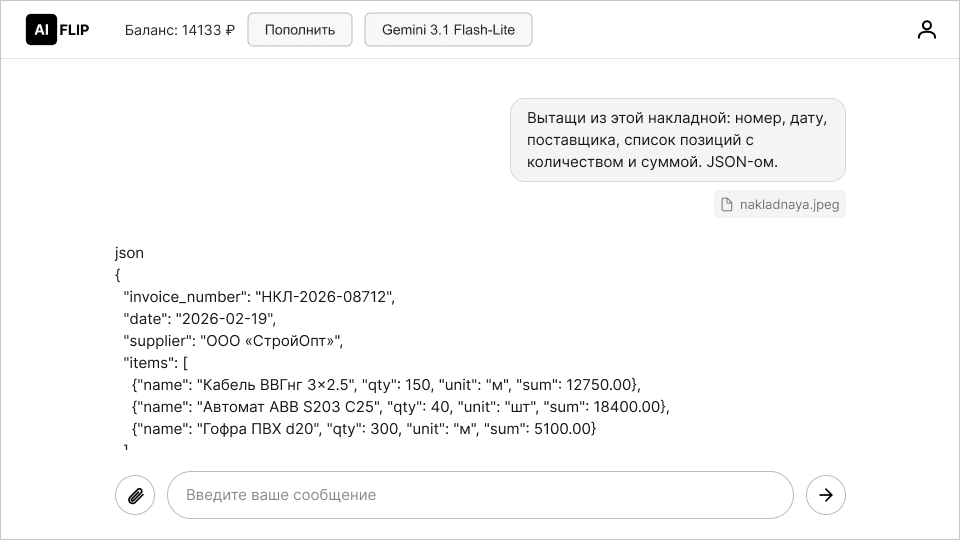
Цифры, которые имеют значение
Вот что заявляет Google и что подтверждают первые тесты:
- Time-to-First-Token — примерно в 2.5 раза быстрее, чем у Gemini 2.5 Flash. Это ощущение «мгновенного» ответа в чате или виджете.
- Скорость генерации — на 45% выше, чем у предшественника. При потоковой обработке тысяч запросов это превращается в реальные часы экономии.
- Arena.ai Elo — 1432. Для «лёгкой» модели это серьёзно.
- GPQA Diamond — 86.9%, MMMU Pro — 76.8%. Не топ среди флагманов, но для своего класса — очень прилично.
А теперь про деньги. Тут начинается самое интересное.
$0.25 за 1 миллион входных токенов (текст, изображения, видео). Полдоллара за миллион аудио-токенов. И $1.50 за миллион выходных — включая thinking-токены.
Переведём в понятное. Допустим, ваш бот обрабатывает 10 миллионов токенов на входе и 5 миллионов на выходе в день. Это $2.50 + $7.50 = $10 в сутки. Триста долларов в месяц. На Pro-модели тот же объём обошёлся бы в 8 раз дороже.
Ну и вишенка: на бесплатном тарифе Google AI Studio Flash-Lite доступна бесплатно — с лимитами по количеству запросов, но для тестирования хватает.
Для каких задач подходит лучше всего
Тут важно быть конкретным. Flash-Lite не «для всего подряд, но дешевле». Она для определённого профиля задач, и именно на них раскрывается.
Массовая классификация и модерация. Представьте: e-commerce-площадка, 500 тысяч отзывов в месяц. Нужно каждый прогнать через фильтр — спам, токсичность, категория товара. Flash-Lite отработает это за копейки. Причём мультимодально: если в отзыве есть фото, модель его тоже «увидит».
Перевод. Не художественный, а рабочий. Описания товаров, интерфейсные строки, FAQ, тикеты поддержки. На потоке в десятки тысяч фрагментов в день разница в стоимости между Flash-Lite и Pro — это бюджет на ещё одного сотрудника.
Извлечение данных из документов. Парсинг накладных, выдёргивание полей из PDF-ок, структуризация входящих писем. Задача формализованная, модели не нужно «думать глубоко» — нужно быстро и точно вытащить нужные поля из знакомого формата.
Агентные сценарии с высоким объёмом. Маршрутизация запросов в саппорте (определить тему → направить на нужного оператора), triage багов, простые действия в пайплайнах. Flash-Lite здесь выступает как быстрый «диспетчер», а сложные кейсы передаёт старшей модели.
Кстати, если ваши задачи ближе к написанию кода — для этого есть модели посильнее. Например Сlaude sonnet 4.6 его можно попробовать у нас в сервисе.
Где Flash-Lite НЕ стоит использовать
Честный блок. Без него статья — реклама.
Сложная математика и логические цепочки. Если задача требует многошаговых рассуждений — теоремы, олимпиадные задачи, сложный дата-анализ с выводами — Flash-Lite будет ошибаться заметно чаще, чем Pro или даже Flash. Это не баг, это trade-off. Модель оптимизирована под скорость, а не под глубину.
Длинные юридические или медицинские рассуждения. Там, где цена ошибки высока, экономия на модели — ложная экономия. Правда, даже флагманы тут требуют проверки человеком, но Flash-Lite ошибётся с большей вероятностью.
Генерация длинных текстов с нюансами. Статья на 5000 слов с аргументацией, эссе, аналитический отчёт. Flash-Lite может выдать «нормально», но без той глубины, которую даст Pro.
Что делать, если часть задач простые, а часть сложные? Гибридный пайплайн. Flash-Lite обрабатывает поток, а нестандартные или сложные кейсы передаёт на Gemini Flash или Pro. Это, впрочем, и есть основной сценарий использования в продакшене — не «одна модель на всё», а каскад.
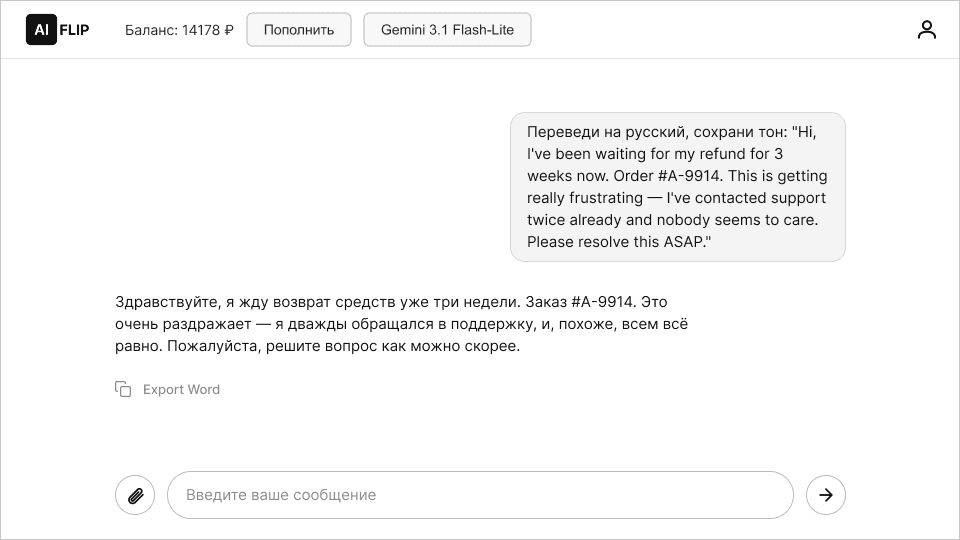
Flash-Lite vs конкуренты: кто в том же классе
Flash-Lite — не единственная «быстрая и дешёвая» модель на рынке. Сравним с ближайшими аналогами.
GPT-5.3 Instant от OpenAI — прямой конкурент по позиционированию. Тоже заточена под скорость и объём. По бенчмаркам они идут близко, но у Flash-Lite ниже цена за входные токены. GPT-5.3 Instant чуть лучше на английском тексте, Flash-Lite — на мультимодальных задачах (картинки, видео, аудио на входе уже «из коробки»).
DeepSeek — другая философия. DeepSeek предлагает очень дешёвый инференс и хорошее качество рассуждений, но профиль задержки другой. Для пакетной обработки DeepSeek может быть выгоднее, а вот для real-time чатов, где критичен TTFT, Flash-Lite выигрывает за счёт инфраструктуры Google.
Если упрощённо:
| Flash-Lite | GPT-5.3 Instant | DeepSeek V3 | |
|---|---|---|---|
| Цена (input, за 1M токенов) | $0.25 | ~$0.40 | ~$0.27 |
| Цена (output, за 1M токенов) | $1.50 | ~$1.60 | ~$1.10 |
| TTFT | Очень низкий | Низкий | Средний |
| Мультимодальность | Текст, фото, видео, аудио | Текст, фото | Текст |
| Лучше всего для | High-volume, real-time | High-volume, текст | Пакетная обработка, рассуждения |
Цифры приблизительные и зависят от тарифа, региона и объёма. Но порядок такой.
Почему это важно именно сейчас
В 2026 году «просто подключить GPT» уже не архитектурное решение, а дефолт. Вопрос сместился: не «используем ли мы LLM», а «сколько это стоит на масштабе и как быстро отвечает».
TTFT в 2.5 раза быстрее — это не абстрактная метрика. Это разница между чат-ботом, который «думает» секунду, и ботом, который начинает отвечать мгновенно. Для пользователя это ощущение живого диалога вместо ожидания. Для бизнеса — выше конверсия в чатах, меньше отвалов.
А стоимость на масштабе… Ну, посчитайте сами. Если у вас 100 миллионов токенов в день, разница между $0.25 и $2.00 за миллион — это $175 в сутки. Больше пяти тысяч долларов в месяц. На одном только входе.
Google, кажется, чётко увидела нишу: не все задачи требуют флагмана. Большинство — не требуют. И модель, которая закрывает 80% рутинных задач за 10% бюджета — это не компромисс. Это рациональность.
Как попробовать из России
Flash-Lite сейчас доступна в preview через Google AI Studio, Gemini API и Vertex AI. Напрямую из России доступ может потребовать VPN или зарубежный аккаунт.
Проще всего — через AI-Flip. Модели Gemini доступны без VPN, оплата в рублях, баланс пополняется токенами. Можно закинуть тестовый запрос и посмотреть, как Flash-Lite справляется именно с вашими данными, прежде чем встраивать в продакшен.
Для тех, кому нужен поиск по интернету в связке с генерацией — есть подборка моделей с поиском.
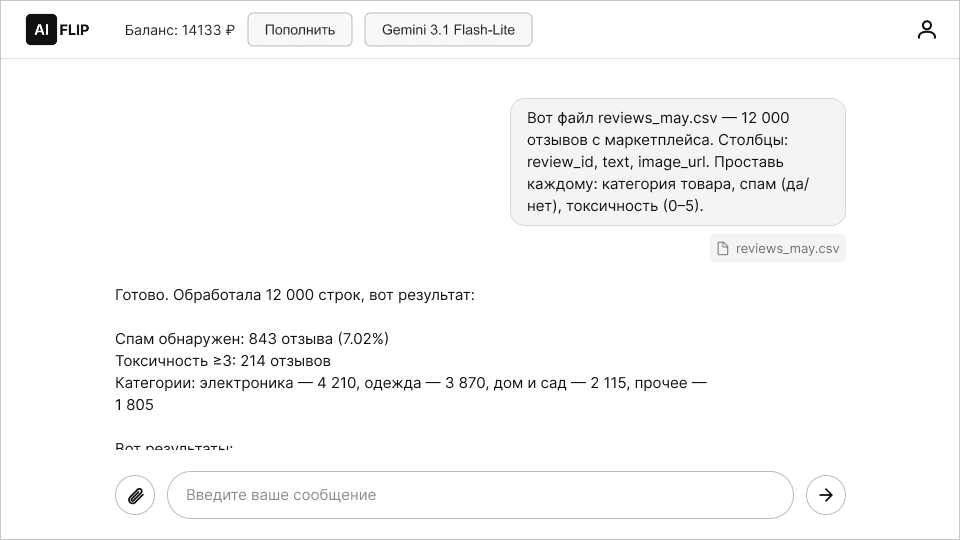
Мини-чеклист: какую модель брать
Не инструкция по внедрению, а продуктовая шпаргалка.
Берите Flash-Lite, если:
- У вас 100K+ запросов в день
- Задачи типовые: классификация, перевод, извлечение полей, маршрутизация
- Критичен TTFT и стоимость токена
- Нужна мультимодальность (картинки, аудио) без переплаты
Берите Flash или Pro, если:
- Задача требует многошагового рассуждения
- Генерируете длинные тексты с аргументацией
- Ошибка в ответе стоит дорого (юридика, финансы, медицина)
Комбинируйте, если:
- Поток смешанный. Flash-Lite на входе фильтрует и классифицирует, сложные кейсы уходят на старшую модель. Это не костыль — это стандартный паттерн в 2026 году.
И в любом случае: тестируйте на своих данных. Бенчмарки — это средняя температура по больнице. Ваш конкретный юзкейс может показать результат лучше или хуже среднего.
Частые вопросы
Q: Flash-Lite — это урезанная версия Flash? A: Не совсем. Она построена на базе Gemini 3 Pro, но оптимизирована под другой профиль: максимальная скорость и минимальная стоимость. Качество рассуждений ниже, чем у Flash, но для типовых задач (классификация, перевод, извлечение данных) разница минимальна.
Q: Можно ли использовать бесплатно? A: Да, на Free-тарифе Google AI Studio Flash-Lite доступна бесплатно, но с ограничениями по количеству запросов. Для тестирования хватит. Через AI-Flip можно работать с моделью без VPN, оплата за фактически использованные токены.
Q: Нужен ли VPN для доступа? A: Для прямого доступа через Google AI Studio из России — может понадобиться. Через AI-Flip — нет.
Q: Flash-Lite поддерживает русский язык? A: Да. Модель мультиязычная. Качество на русском чуть ниже, чем на английском (это нормально для всех моделей Google), но для задач классификации и перевода — вполне рабочее.
Q: Стоит ли переходить с DeepSeek на Flash-Lite? A: Зависит от задачи. Если вам важна скорость первого токена и real-time отклик — Flash-Lite выигрывает. Если важнее качество рассуждений при низкой цене и пакетная обработка — DeepSeek может быть лучше. Лучший способ решить — прогнать оба варианта на реальных данных.