
Как загрузить файл в нейросеть: пошаговая инструкция для новичков и продвинутых пользователей
Самая полезная кнопка в нейросети — самая незаметная.
Маленькая скрепка рядом с полем ввода, которую половина пользователей вообще
не видит. А зря: именно она превращает ИИ из «собеседника, с которым можно поболтать» в инструмент, который читает за вас договоры, разбирает таблицы и конспектирует статьи. Вечер работы сжимается до пятнадцати минут.
Но только если знать, как этой скрепкой пользоваться.
Загрузка документов одна из самых полезных функций современных ИИ-сервисов,
и при этом одна из самых недооценённых. Многие до сих пор копируют текст в чат кусками, потому что не замечают маленькую кнопку «скрепка» рядом с полем ввода.
А зря: нейросеть умеет читать PDF, Word, Excel, CSV, изображения с текстом, иногда даже видео и аудио.
В этом гайде разберём, как загружать файлы в разные сервисы, какие форматы лучше работают, как готовить документы перед загрузкой и что делать в России, где половина известных нейросетей напрямую не открывается.

Самый простой способ: скрепка и перетаскивание
Базовый сценарий выглядит одинаково почти во всех сервисах. Открываете чат, видите поле для ввода сообщения. Рядом с ним иконка скрепки или плюсика.
Нажали, выбрали файл с компьютера, дождались загрузки, написали запрос. Всё.
После загрузки файл появится либо отдельным блоком над полем ввода,
либо как вложение к сообщению. Дальше пишете запрос: «Сделай краткое содержание», «Найди все упоминания дат», «Объясни пятый пункт простыми словами».
Нейросеть прочитает файл и ответит уже с учётом его содержимого.
Работу с такими задачами лучше начать с ChatGPT.
Что важно знать про лимиты. Типичные ограничения: до 50 МБ на один файл и до 5 файлов за один запрос. Это усреднённая цифра, у каждого сервиса свои рамки: где-то можно 10 МБ, где-то 100, где-то загружать только PDF, а Word придётся конвертировать.
Если файл не загрузился — первое, что стоит проверить, это размер и формат.
Какие форматы работают лучше всего
Тут начинается интересное. Нейросеть теоретически умеет читать почти всё, но качество ответа сильно зависит от того, в каком виде вы скормили ей документ.
Один и тот же отчёт в PDF может разобраться в одной модели идеально,
а в другой превратиться в кашу.
Для текстовых документов лучше всего работают обычный TXT, Markdown и Word.
PDF тоже подходит, но с оговоркой: если он сделан из сканов (то есть фактически это картинки страниц), нейросети будет тяжело.
Ей придётся распознавать текст, то часть символов потеряется. Если нет возможности использовать специализированные сервисы, то задачи со сканами лучше отдать мультимодальным моделям, по типу Google Gemini.
Но стоит учитывать, что Текстовый PDF, который сгенерирован напрямую из документа, читается отлично.
С таблицами история сложнее. Логично же загрузить XLSX: это родной формат Excel, в нём всё аккуратно. Но на практике, как показывает практика, CSV надёжнее.
Причина простая: XLSX содержит кучу служебной разметки, формул, объединённых ячеек, форматирования, и нейросеть иногда путается в этой структуре.
CSV это просто текст с запятыми. Его невозможно неправильно распознать.
Если у вас таблица в Excel и её надо проанализировать:
сохраните копию в CSV (Файл → Сохранить как → CSV) и загружайте именно её.
Изображения с текстом — отдельная история. Скриншот документа, фотография страницы книги, инфографика. Основные модели (ChatGPT, Claude, Gemini) распознают текст с картинки и работают с ним так же, как если бы вы загрузили PDF.
Но если на скриншоте мелкий шрифт или плохое освещение на фото, то результат будет хуже.
Список того, что обычно поддерживают популярные сервисы:
- PDF — почти везде, основной формат
- DOCX, DOC — большинство крупных моделей
- XLSX, CSV — тут CSV предпочтительнее
- TXT, Markdown — самые надёжные форматы
- PNG, JPG, WEBP — для документов-картинок и скриншотов
- PPTX — поддерживают не все, проверяйте конкретный сервис
Гигиена работы с файлами: как готовить документ
А вот это раздел, который большинство гайдов пропускает.
Скормить файл «как есть» — нормально для коротких документов.
Но если у вас договор на 80 пунктов или отчёт на 200 страниц, подготовка решает примерно всё.
Специализированные сервисы для анализа больших документов справляются и с такими объёмами. Но при условии, что PDF структурирован: есть содержание, понятные заголовки, нет лишних страниц вроде сканов подписей и печатей в конце.
Если документ свалкой — нейросеть тоже даст ответ, но шансы на ошибку резко вырастут.
Что стоит сделать перед загрузкой:
- Удалите мусорные страницы. Пустые листы, страницы только с печатями, дублирующиеся колонтитулы. Всё, что не несёт информации, отвлекает модель.
- Проверьте, что текст в PDF это текст, а не картинка. Откройте PDF и попробуйте выделить кусок мышкой. Выделяется? Отлично. Не выделяется, выделяется вся страница целиком как блок? Это скан.
- Разбейте слишком большие файлы. Если документ на 300 страниц, а лимит сервиса в 50 МБ то, проще, загрузить две части по 150 страниц.
С явным указанием: «Это первая половина договора, жди вторую». - Для таблиц почистите данные. Уберите объединённые ячейки, оставьте один заголовок строкой, удалите пустые столбцы.
- Дайте файлу осмысленное имя. «Договор_аренды_офиса_2026.pdf» лучше, чем «Документ_3_финал_правки_v2(1).pdf». Нейросеть видит имя файла и иногда использует его как контекст.
И ещё одна штука, которую редко упоминают. Если документ на иностранном языке — сразу пишите промпт на этом же языке. Нейросеть лучше поймёт, что вы хотите от английского контракта, если запрос тоже будет по-английски.
Это не правило, но эмпирически работает.
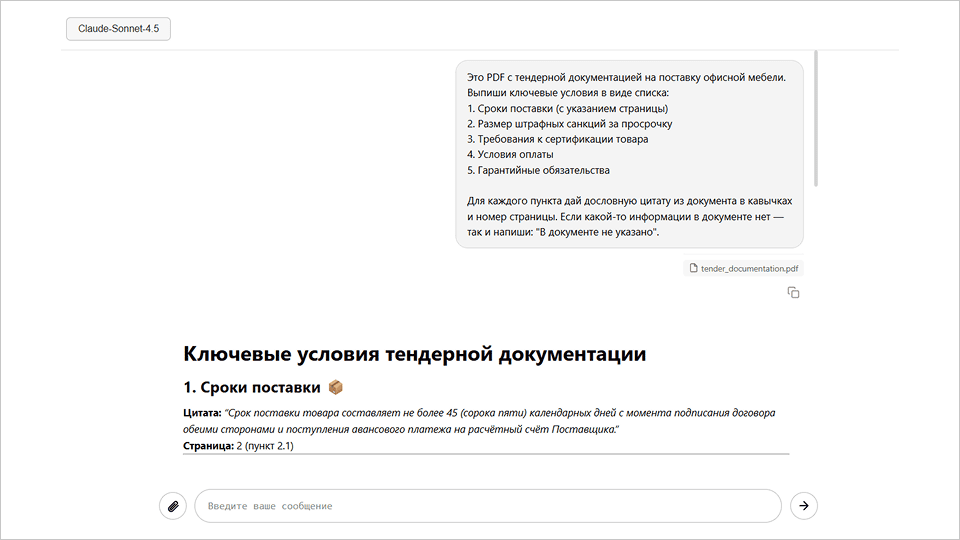
Работу с PDF мы расмартивали на примере конкретной модели от Google.
Реальные сценарии: договоры, отчёты, конспекты
Теория теорией, а вот что работает на практике.
Анализ договоров. Загружаете PDF договора, спрашиваете: «Найди все условия, которые могут быть невыгодны для арендатора. Перечисли пункты с номерами и объясни,
в чём риск». Получаете список с нумерацией и комментариями.
Это не заменяет юриста, но за пять минут даёт понимание, на что обратить внимание. Именно анализ договоров один из самых частых сценариев использования нейросетей
в малом бизнесе.
Финансовые отчёты. CSV с продажами за год, запрос: «Найди месяцы с самой большой просадкой, выдели топ-5 товаров по выручке, посчитай средний чек по кварталам». Нейросеть выдаст цифры и комментарий. Идеально подходит для тех, кто не хочет писать формулы в Excel.
Конспекты длинных документов. Загружаете научную статью или книгу главу, просите: «Сделай краткое содержание в 10 пунктах, выдели основные тезисы автора, перечисли использованные источники». За 30 секунд получаете то, на что человек тратит час.
База знаний из нескольких файлов. Это менее очевидный сценарий. Загружаете не один документ, а сразу несколько: например, методичку, ваши конспекты и статью по теме. Потом задаёте вопросы, и нейросеть отвечает, опираясь на всё сразу.
Полезно для подготовки к экзамену или для разбора темы с разных сторон.
Извлечение данных. Скриншот меню ресторана: «выпиши все блюда с ценами в таблицу». Фото счёта: «посчитай, сколько с каждого, если делить поровну на 4».
PDF выписки из банка: «сгруппируй траты по категориям».
Тут нейросети особенно хороши, потому что задача рутинная, а человеку скучная.
Где упираешься в потолок
Будем честны: не всё работает так гладко, как в обещаниях разработчиков.
Первая проблема это галлюцинации в длинных документах.
Если файл большой, нейросеть может «забыть» начало к моменту, когда дошла до конца. Или выдумать пункт, которого в договоре нет. Поэтому критичные вещи всегда проверяйте по оригиналу, особенно цифры, даты и формулировки в юридических текстах.
Нейросеть помощник, а не нотариус.
Вторая в сложных таблицах. Объединённые ячейки, многоуровневые заголовки,
сводные таблицы в Excel часто превращаются в кашу при чтении.
Если структура нетривиальная, лучше вручную упростить или экспортировать в CSV.
Третья это рукописный текст и плохие сканы. Распознавание реально работает,
но не магически. Конспект лекции, написанный от руки, или потёртая ксерокопия
с печатями могут дать на выходе много мусора.
Тут проще перепечатать вручную.
И ещё момент про конфиденциальность. Если вы загружаете коммерческий договор
или персональные данные — помните, что файл уходит на сервера сервиса.
Большинство крупных провайдеров заявляют, что не используют пользовательские данные для обучения, но политика разная у каждого. Для совсем чувствительных документов
либо обезличивайте перед загрузкой (заменяйте имена и суммы), либо используйте локальные модели на своём компьютере.
Доступность из России: что работает, а что нет
Тут начинается часть, ради которой многие и читают такие гайды. В России половина известных сервисов прямо в браузере не открывается.
ChatGPT — официальный сайт chatgpt.com заблокирован для российских IP, приложений нет в наших магазинах, для регистрации API нужны иностранный номер и карта.
Google Gemini — gemini.google.com, AI Studio, NotebookLM из РФ не открываются: прямой доступ закрыт региональными ограничениями.
Claude от Anthropic — та же история, claude.ai заблокирован, регистрация API требует иностранных реквизитов.
Что работает напрямую без VPN:
- GigaChat от Сбера это российский сервис, доступен полностью, версия 2.0 нормально работает с документами
- YandexGPT — версия 5.1 Pro поддерживает работу с файлами, тоже без VPN
- DeepSeek уже китайский сервис, открывается из РФ напрямую
- Mistral — европейский, в большинстве регионов открывается без VPN
GigaChat и YandexGPT нормальные нейросети для базовых задач.
Справятся с тем что бы прочитать договор, сделать выжимку отчёта, поработать с таблицей на русском.
Но если нужны последние версии GPT, Claude Opus или Gemini, простой логикой «открыть и пользоваться» не получится.
Решений два: VPN или агрегатор. С VPN всё понятно — установили, выбрали страну, зарегистрировались на иностранную почту, оплатили иностранной картой.
Это работает, но муторно.
Агрегатор — посредник, который сам подключён к зарубежным API и предоставляет вам интерфейс на русском. AI-Flip как раз такой сервис: открывается с российского IP без VPN, оплата токенами в рублях с обычной российской карты, в одном окне доступны и ChatGPT, и Claude, и Gemini, и DeepSeek.
Загрузка файлов работает на уровне агрегатора. То есть кнопку «скрепка» вы используете точно так же, как в оригинальном сервисе, а под капотом запрос уходит в нужную модель.
Это удобно ещё и тем, что не надо заводить отдельные аккаунты в каждом сервисе и платить отдельную подписку. Один баланс на все модели.
Как загрузить файл через AI-Flip: пошагово
Если решили попробовать через агрегатор, процесс такой:
- Регистрация на ai-flip.ru — по email, без иностранных номеров
- Пополнение баланса — обычной российской картой, любая сумма от небольшой стартовой
- Выбор модели в чате — выпадающий список, рядом с каждой моделью показано, сколько стоит токен
- Загрузка файла — та же самая скрепка, всё интуитивно
- Запрос — пишете на русском или любом другом языке, что нужно сделать с файлом
Списание идёт по факту использования. Загрузили один PDF, спросили один вопрос, потратили условные пять рублей.
Никаких ежемесячных подписок, никаких блокировок «вы превысили лимит сообщений
за день».
Часто задаваемые вопросы
- Какой максимальный размер файла можно загрузить?
Зависит от модели. Большинство сервисов держат лимит около 50 МБ на файл и до 5 файлов за один запрос. Если документ больше — разбейте на части или сожмите PDF.
- Почему таблица из Excel загрузилась, но нейросеть путается в данных?
Скорее всего, в файле объединённые ячейки или сложная структура. Сохраните копию в CSV — нейросети читают этот формат гораздо точнее.
- Нейросеть «галлюцинирует» по длинному документу. Что делать?
Разбейте файл на смысловые части и работайте с ними по очереди. Или загружайте в модель с длинным контекстом — Claude и Gemini держат сотни страниц лучше большинства конкурентов.
- Можно ли загрузить отсканированный документ?
Можно, но качество распознавания зависит от чёткости скана. Если страницы кривые или мелкие — сначала прогоните через OCR сервисы, а потом загружайте получившийся текстовый PDF.