
ИИ для PDF: как нейросети читают документы за вас и какие сервисы работают в России в 2026
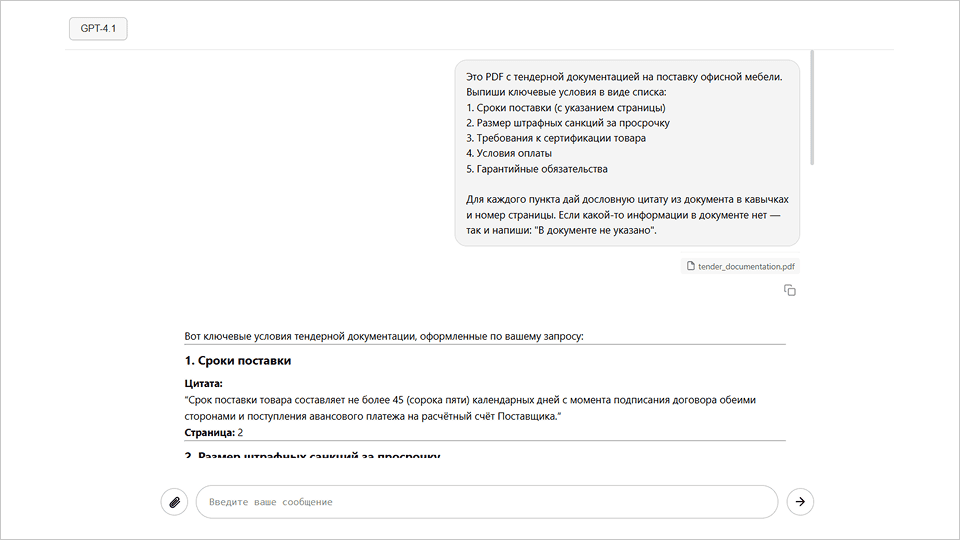
180 страниц тендерной документации. Где-то внутри находяться сроки поставки, штрафные санкции и три абзаца про сертификацию, которые сегодня важнее всего остального. Раньше это означало четыре часа чтения с маркером в руках. Сейчас, займет около десяти минут диалога с нейросетью, которая сама находит нужные пункты и приводит цитаты
с указанием страниц.
Нейросети научились принимать PDF, разбирать его и отвечать на конкретные вопросы
по тексту: где написано про штрафы, какие там цифры, что в приложении №3.
На длинных документах это экономит не минуты, а часы.
Эта статья про то, какие именно ИИ-инструменты работают с PDF, что они умеют, где врут. И самое главное, какие из них реально доступны из России в 2026 году без VPN и иностранных карт. Разберём пять задач, три типа сервисов, сравним модели и пройдёмся по сценариям для бухгалтера, маркетолога, юриста и студента.
Что вообще умеет ИИ для PDF
Если убрать маркетинговый шум, у нейросетей в работе с PDF пять реальных задач. Конкретные вещи, которые экономят время.
Суммаризация. Загружаете отчёт на 80 страниц, получаете пересказ на одну. Можно попросить общее саммари, можно по разделам. Хорошие модели вроде Claude Sonnet 4.6 или GPT-5 не просто пересказывают первые абзацы, а выделяют действительно главное. Цифры, выводы, изменения по сравнению с предыдущим периодом.
Вопросы и ответы по документу. Это не та же суммаризация.
Тут вы задаёте конкретный вопрос: «На какой странице говорится про условия расторжения?», «Какая сумма штрафа за просрочку поставки?», «Что в этом договоре написано про интеллектуальную собственность?».
Дальше получаете точечный ответ. Желательно со ссылкой на страницу.
Извлечение данных из таблиц и графиков. Бухгалтерский отчёт, сравнение тарифов, статистика по регионам. Модель достаёт цифры в виде таблицы или CSV, который потом можно вставить в Excel. Тут есть нюансы, с простыми таблицами справляются почти все.
С многоуровневыми и графиками, только лучшие модели, и всё равно с проверкой.
Перевод PDF на другой язык. Не просто «прогнать через переводчик», а перевести
с сохранением структуры. Особенно хорошо работает в связке: попросить и перевод,
и краткое саммари на русском. Экономит время, когда читаете иностранный отчёт
или научную статью.
OCR — распознавание текста в сканах. Старый акт сверки, фотография договора
с телефона, скан методички ФНС. Современные мультимодальные модели
(GPT-5, Claude, Gemini) умеют читать текст с изображений, хотя качество всё ещё уступает специализированным OCR-системам. Для несложных сканов хватает.
Работу ИИ с PDF на примере конкретной модели от Google мы описывали в отдельной статье.

Три типа инструментов: чем они отличаются
Когда говорят «ИИ для PDF», обычно имеют в виду три разные вещи. Их полезно различать, потому что задачи у них разные.
Универсальные чат-боты с загрузкой файлов. ChatGPT, Claude, Gemini.
Загружаете PDF прямо в чат и работаете с ним как с любым другим запросом.
Плюсы: одна и та же модель отвечает и на вопросы по документу, и на общие вопросы, можно в том же диалоге попросить «а теперь напиши на основе этого пост в соцсетей». Минусы: нужен доступ к самим моделям, у каждой свои ограничения по размеру файла.
Под разные задачи оптимальнее использовать нужные модели.
Нет смысла включать «глубокое рассуждение» для ответа на PDF в одну страницу.
А в каких случаях лучше подойдет конкретная модель, смотрите на примере Gemini.
Специализированные PDF-сервисы. Заточены конкретно под работу с документами: интерфейс с подсветкой страниц, кнопки «суммаризировать», «перевести», «извлечь таблицу».
То есть, уже полноценный редактор со встроенным ИИ (можно ещё и подписать документ, скрыть персональные данные, объединить файлы).
Агрегаторы. Сервисы, которые дают доступ к нескольким моделям через один интерфейс. AI-Flip это пример такого агрегатора с прицелом на российских пользователей.
Удобство в том, что можно в одном кабинете попробовать тот же документ через ChatGPT, потом через Claude.
Сравнить ответы и не платить трём разным сервисам.
Чёткой границы между категориями нет. Но интуитивно: если работаете с PDF время от времени и хотите универсальный инструмент: берите чат-бот или агрегатор.
Если занимаетесь документами каждый день и нужны редактирование плюс ИИ, то специализированный сервис.
Какая модель что умеет в работе с PDF
У каждой модели свои сильные стороны. Для коротких документов разница не очень заметна. Для длинных и сложных она критична.
| Модель | Контекст | Где сильна | Где слабее |
| Claude Opus 4.7 / Sonnet 4.6 | до 200K токенов (~500 стр.) | длинные документы, точная работа с цитатами и таблицами, аккуратные ответы | хуже работает с изображениями внутри PDF, чем GPT |
| GPT-5 / GPT-4o | 200K+ токенов | универсальность, мультимодальность, графики и схемы | бывает «фантазирует» на длинных документах, если не указать ограничения |
| Gemini 3 Pro | до 1M+ токенов в спец. режимах | очень длинный контекст, документы из Google Workspace | в РФ официальный доступ ограничен, см. ниже |
| GigaChat, YandexGPT | меньше, но достаточно для большинства задач | русский язык, локальная инфраструктура | контекст меньше, общая «эрудиция» уступает Claude и GPT |
Один PDF-документ — это в среднем 400–500 токенов на страницу. То есть в контекст
в 200 тысяч влезает 400–500 страниц текста. На практике этого хватает почти под любую офисную задачу: годовой отчёт, методичка, том договора с приложениями.
Если документ больше, то приходится дробить. Либо загружать частями и просить модель работать с каждым куском отдельно, либо использовать Gemini с его длинным контекстом, либо специализированные сервисы, которые сами разбивают PDF на чанки и ищут по нему через embeddings.
Claude в 2026 году это лучший выбор для длинных юридических и аналитических документов. На договоре в 120 страниц он реже теряет нить и аккуратнее цитирует.
GPT-5 уже универсал. Отлично работает с PDF, в которых много изображений, схем
и графиков, а ещё с ним удобно сразу переходить к творческим задачам.
Gemini с миллионом токенов хорош, когда документов реально много, но об ограничениях из РФ нужно поговорить отдельно.
Как это работает в России в 2026
Это самый болезненный пункт. Если вы откроете десять обзоров «лучших нейросетей
для PDF», в восьми из них будут советы вроде «зайдите на gemini.google.com и загрузите файл». Из России это просто не работает.
Что заблокировано или требует иностранных реквизитов:
- OpenAI. chatgpt.com и chat.openai.com заблокированы для российских IP. Приложения ChatGPT в App Store и Google Play в РФ недоступны. API OpenAI — регистрация требует иностранный номер телефона и иностранную карту.
- Anthropic. claude.ai заблокирован для российских IP. Приложения ограничены. API требует иностранные реквизиты.
- Google AI. gemini.google.com, AI Studio, NotebookLM, Vertex AI, портал ai.google.dev — заблокированы. Gemini в Gmail и Docs через Google One AI Premium — недоступен. Мобильное приложение Gemini в Android — недоступно.
Что работает напрямую:
- DeepSeek открывается из РФ, регистрация по email, API доступен.
Но нельзя оплатить расширенные функции, только базовый доступ. - Mistral / Le Chat работает напрямую, API доступен.
- GigaChat и YandexGPT российские, проблем с доступом нет по определению.
- Gemini в Google Search. Встроенные ответы в поисковой выдаче работают,
но это не полноценный чат с PDF.
Что делают агрегаторы. Сервисы вроде AI-Flip используют доступ к API всех крупных моделей через юрлица за рубежом, а пользователю предоставляют единый интерфейс
с оплатой российской картой.
Технически вы работаете с тем же ChatGPT или Claude: только подключение идёт через посредника. VPN не нужен, иностранная карта не нужна, регистрация по email или номеру телефона.
Биллинг в AI-Flip устроен через токены: пополняете баланс в рублях, платите по факту использования. Удобно тем, что нет фиксированной подписки. Если месяц не работали
с PDF, ничего не списывается.
Где ИИ плохо работает с PDF
Теперь про минусы. Иначе вы загрузите договор, поверите ответу модели и подпишете
не то.
Галлюцинации на длинных документах. Если документ большой и вопрос неконкретный, модель может «додумать» то, чего в тексте нет. Особенно этим грешит GPT на самой границе контекста. Лечится правильным промптом (см. следующий раздел),
но полностью не уходит.
Цифры и таблицы. ИИ путает цифры. Не часто, но регулярно. Если в договоре сумма
1 248 500, а в соседней таблице 1 248 000, модель может склеить их или указать неверно. Для бухгалтерии и юридических документов критичные числа всегда перепроверяйте.
Сканы плохого качества. Если PDF это фотография документа, сделанная на телефон
под углом, с тенями и заломами, OCR ошибается. Цифры путает с буквами (0 и О, 1 и l),
даты читает неверно. Для таких случаев лучше сначала прогнать через специализированный OCR (ABBYY FineReader или аналоги), потом уже отдавать в ИИ.
Графики и сложные таблицы. Многоуровневые таблицы с объединёнными ячейками, графики с подписями до сих пор слабое место нейросетей. Лучше всех справляется GPT-5 благодаря мультимодальности, но и он ошибается на 10–20%. Для финансовых отчётов это много.
Как ставить задачу, чтобы модель не врала
Большая часть проблем с ИИ для PDF: это не ограничения модели, а кривые промпты. Несколько простых правил резко повышают качество ответов.
Дробите большой запрос на этапы.
Не «проанализируй договор и скажи, есть ли там что-то опасное», а «выпиши все пункты про штрафы и санкции», потом «выпиши условия расторжения», потом «найди упоминания персональных данных». На каждом шаге модель работает точнее.
Прямо просите отвечать только на основе документа. Формулировка вроде такой работает почти всегда: «Отвечай только на основе загруженного PDF. Если ответа в документе нет, так и напиши: «В документе этой информации не нашёл«. Не додумывай и не привлекай внешние знания.»
Просите указывать страницы и цитаты. «Для каждого ответа укажи номер страницы
и приведи дословную цитату из документа в кавычках.» Это превращает ответ модели
в проверяемое утверждение. Вы сразу можете открыть нужную страницу и сверить.
Перепроверяйте критичные данные. Договоры, бухгалтерские документы, медицинские карты, юридические заключения, словом, всё, что имеет последствия. ИИ это первый прогон, который экономит время. Финальная сверка уже глазами или с участием специалиста.
Что выбрать под свою задачу
Для большинства офисных пользователей в России в 2026 году разумный путь — начать с агрегатора. Попробовать одну и ту же задачу через разные модели и понять, какая лучше работает именно для ваших документов.
Потом, если нужно, доплачивать за специализированный инструмент.
Как начать через AI-Flip
Регистрация по email. VPN не нужен, иностранная карта не нужна.
После регистрации пополняете баланс рублями (через карту российского банка).
Это токены, которые расходуются по мере использования. Дальше выбираете модель из списка: Claude Sonnet или Opus для длинных документов, GPT-5 для универсальных задач и работы с изображениями, Gemini для очень больших файлов.
Загружаете PDF в чат и работаете.
Один и тот же документ можно прогнать через несколько моделей и сравнить ответы.
На сложных юридических текстах это иногда помогает поймать разночтения: одна модель пропустила пункт, другая нашла.
Часто задаваемые вопросы
- Какая нейросеть лучше всего читает PDF?
Универсального ответа нет. Для длинных юридических и аналитических документов в 2026 году лучший выбор — Claude Opus 4.7 или Sonnet 4.6: большой контекст, аккуратная работа с цитатами, реже галлюцинирует. Для PDF с большим количеством изображений и схем — GPT-5 за счёт мультимодальности. Для очень больших документов (тысячи страниц) — Gemini 3 Pro с расширенным контекстом.
- Можно ли пользоваться ChatGPT для PDF в России?
Напрямую через chatgpt.com — нет, сервис заблокирован для российских IP, регистрация требует иностранный номер. Через агрегаторы вроде AI-Flip — да, без VPN, с оплатой российской картой. Технически вы работаете с тем же ChatGPT через посредника.
- Сколько страниц PDF может обработать ИИ за раз?
Зависит от модели. Claude Sonnet 4.6 и GPT-5 — около 400–500 страниц обычного текста за один запрос (200K токенов). Gemini в специальных режимах — больше тысячи. Если документ не влезает, его дробят на части. Специализированные PDF-сервисы умеют делать это автоматически через поиск по тексту.
- Что лучше: ChatGPT, Claude или Gemini для PDF?
Если упрощать: Claude — для длинных текстов, где важна аккуратность и цитаты. ChatGPT — для универсальных задач и PDF с картинками/графиками. Gemini — когда документ очень большой или вы работаете в Google Workspace. На практике многие пользователи держат доступ ко всем трём через агрегатор и выбирают модель под конкретный документ.